Software, Tools, Skripte für die maschinelle Sprachverarbeitung
An dieser Stelle stellen wir kleinere Softwarelösungen, Tools und Programmierskripte der maschinellen Sprachverarbeitung zur nicht-kommerziellen Nutzung zur Verfügung. Diese Seite befindet sich noch im Aufbau.
CorpusTransfer
Corpustransfer ist ein kleines, aber wirksames Windows-Tool, um Korpora automatisch zu lemmatisieren und/oder zu Wortart-taggen. Dabei wird im Hintergrund auf TreeTagger (Helmut Schmid, Stuttgart) zuückgegriffen, dessen Listenergebnisse ausgewertet und nach verschiedenen Filteroptionen wieder zu Volltext-Korpora transformiert.
Damit wird es möglich, auch mit Analysetools, die keine Annotationen berücksichtigen (wie AntConc), dennoch grammatische Analysen i.w.S. durchzuführen (z.B. Wortartfrequenzen, Konkordanzabfragen zu spezifischen Wortart-Mustern, automatische Herausfilterung von bestimmen Wortarten aus Texten uäm.).
Die aktuelle Version von Corpustransfer (v1.5) kann hier als ZIP-File und unter den Bedingungen der Creative Commons Licence heruntergeladen werden; Zip einfach in einen Ordner entpacken. Für die Anwendung sind TreeTagger (inkl. aller dafür notwendigen Dateien) sowie eine Perl-Installation Voraussetzung. Dem Programm ist eine Kurzanleitung (in Deutsch) beigefügt.
Bugs: Description wird nicht angezeigt. Siehe stattdessen die Dokumentation zu TreeTagger (Helmut Schmid, Stuttgart).
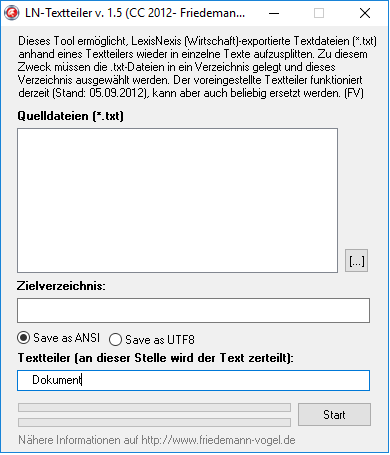
LexisNexis-Textteiler
Der LN-Textteiler dient zur Wieder-Aufsplittung von Paketdateien (*.txt mit vielen Einzeltexten) in einzelne Textdateien. Die LexisNexis-Textdateien müssen nach dem Export bzw. Herunterladen als TXT-File lediglich in ein Verzeichnis gelegt und im Tool geladen werden. Der LN-Textteiler zerlegt diese Dateien anschließend nach einem voreingestellten (aber individuell anpassbaren) Teilerschlüssel, extrahiert Medium und Erscheinungsdatum und speichert letztere im Dateinamen wahlweise im UTF8- oder ANSI-Format ab.
Das Tool funktioniert derzeit mit allen LexisNexis-TXT-Exporten (Stand: 19.11.2012). Sollte es einmal nicht mehr funktionieren (z.B. weil LexisNexis den Formatstandard verändert hat), wäre ich für einen Hinweis sehr dankbar. Generell übernehme ich keinerlei Garantie oder Haftung im Falle von Schäden bei Anwendung der hier zur Verfügung gestellten Freeware.
Das Tool kann hier als Stand-Alone-EXE von meinem Server heruntergeladen werden.
Bekannte Bugs und ihre Lösung: Fehlermeldung: „Datei XYZ kann nicht gespeichert werden“. – Das Tool bricht ab und muss neu gestartet werden. Lösung: Das Tool zerteilt die Texte anhand des Textteilers und filtert dann Medientitel und Erscheinungsdatum heraus als Teil des jeweiligen Dateinamens. Wenn in einem der Medientitel irgendwo ein Zeichen ist, das für Dateinamen nicht zulässig ist (insb. „/“ oder „\“), dann entsteht diese Meldung. Daher schauen Sie, bei welchen Dateien (und Titeln) die Fehlermeldung genau kommt und suchen und ändern Sie in den Quell-TXT-Dateien die entsprechenden Medientitel mit Copy&Paste (z.B. „/“ durch „_“ ersetzen). Anschließend starten Sie das Programm neu. Die neue Version (1.5) umgeht das Problem, in dem derartige Dateien automatisch abgespeichert werden als „MetadataEncoding_failed“.

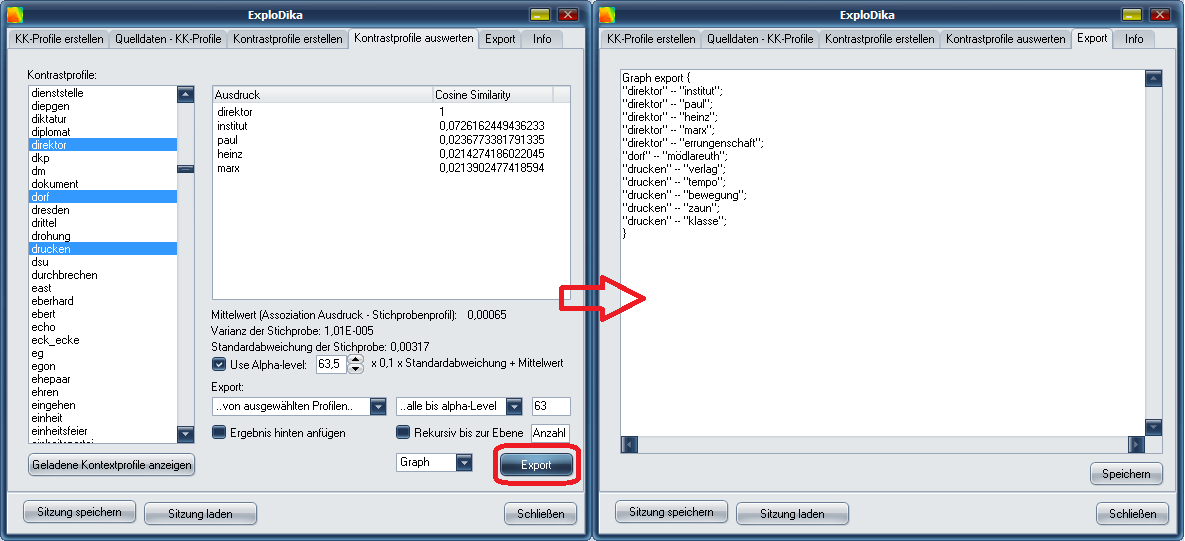


ExploDika – Tool für eine explorative Diskurskartographie
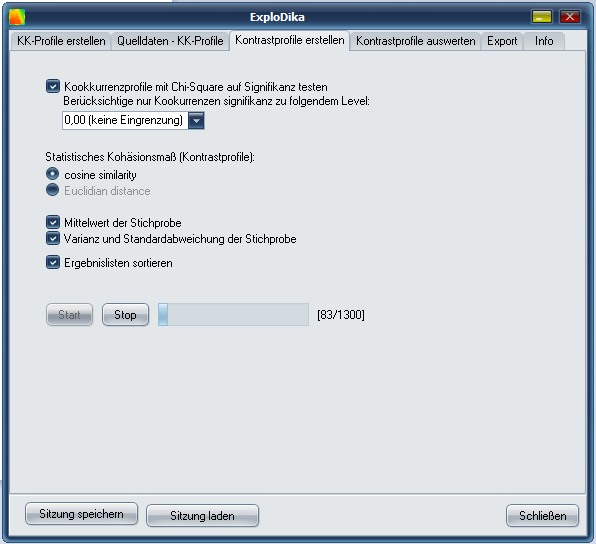
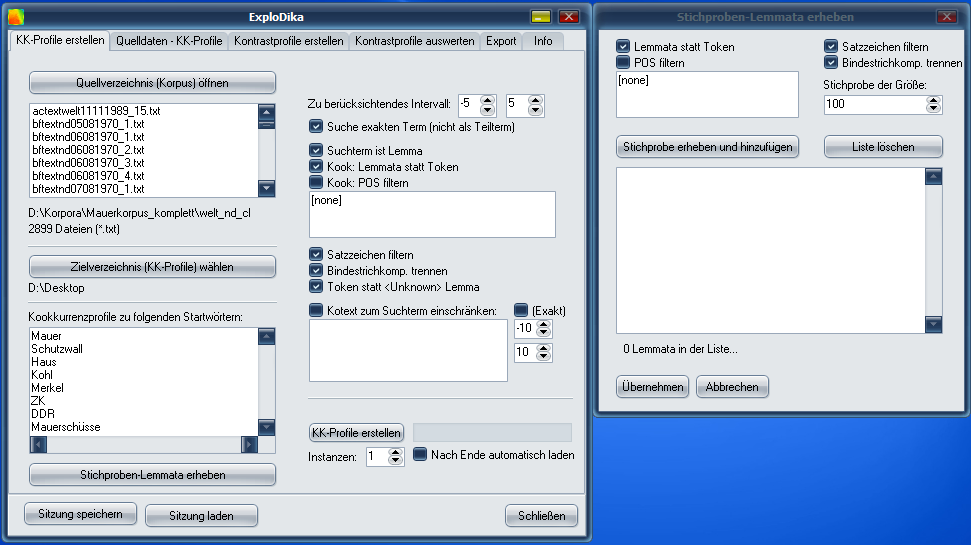
ExploDika ist ein frühes windowsbasiertes Tool zur semiautomatischen Ermittlung von Sprachgebrauchsähnlichkeit (Quasi-Synonymie- und Wortfeldanalysen) auf Basis von annotierten Korpora, Kookkurrenzanalysen und statistischen Verfahren.
Der Name der non-commercial Freeware resultiert aus ihrer Anwendung im Rahmen einer explorativen Diskurskartographie: das Tool erzeugt induktive Daten, die mit Hilfe externer Software als self-organized-maps oder „Diskurskarten“ visualisiert und zum Zwecke von linguistischen Diskurs- und Imageanalysen in Lehre und Forschung eingesetzt werden können.
ExploDika verfügt derzeit über folgende Funktionen:
- Ausschließliche Verarbeitung von TreeTagger-annottierten Textkorpora;
- Gute Performance auf Grund von Hash- und Multithread-Verarbeitung;
- Automatische Kookkurrenzanalysen und daraus resultierende Erstellung von Kotextprofilen zu n Ausgangsausdrücken;
- Auswertung und Gewichtung der Kookkurrenzanalysen mittels Chi-Square-Signifikanztest;
- Matrixanalyse zu n Kotextprofilen und Berechnung relativer Kotextähnlichkeit mittels des Assoziationsmaßes Cosine Similarity (Lee 1999);
- Automatische Ziehung einer randomisierten Stichprobe zur Ermittlung einer durchschnittlichen Ähnlichkeit aller n Ausgangsausdrücke bzw. Kotextprofile; Berechnung von Mittelwert, Varianz und Standardabweichung;
- Ermittlung eines Schwellwertes zur Filterung von ‚ähnlichen‘ gegenüber ‚unähnlichen‘ Kotextprofilen mittels Stichproben-Mittelwert, -standardabweichung und einem manuellen Faktor (alpha); – für die Entwicklung dieser Idee gilt mein Dank Prof. Dr. Sebastian Padó (Computerlinguistik, Universität Heidelberg);
- Export der Kookkurrenz- bzw. Kotextprofile und der Kontrastprofile;
- Filterung und Export der Ergebnisse im DOT-Format (für Import und Verarbeitung in Netzwerkanalyseprogrammen wie Gephi oder GraphViz);
- Speichern und Laden von Arbeitssitzungen zur Reduktion von Rechenaufwand.
TextKey
TextKey (2009) ist ein kleines Windows-Tool, um die Zusammenstellung individueller Text-Korpora zu erleichtern. Mit Hilfe von globalen Hotkeys (Vordefinierten Tastenkombinationen) können markierte Textteile in anderen Programmfenstern (z.B. im Internetexplorer) direkt in TextKey kopiert und vorannotiert werden. Die Auszeichnung der verschiedenen Textteile erlaubt anschließend eine automatische Aufnahme in Datenbanken oder sonstige Weiterverarbeitungen.
Funktionsbreich der Registerkarten:
- Textview: Textansicht, in die Textteile automatisch eingefügt werden.
- Delete Tags: Bereits getaggte Textdateien können von ihren Auszeichnungen bereinigt werden.
- TEXTtoXML: Getaggte Textdateien können in XML umgewandelt und damit in Datenbanken importiert werden (Getestet: Access 2007).
- Controls: Voreinstellungen für das automatische Einfügen von Textteilen.
- About: Versionsangaben und Lizenzbestimmungen.
Die aktuelle Version von Textkey kann hier als ZIP-File und unter den Bedingungen der Creative Commons Licence heruntergeladen werden; einfach entpacken und Textkey starten (keine Installation nötig).
ANSI-UTF8-Text-Codierer
Das Tool speichert alle TXT-Dateien eines Verzeichnisses in dem Format ANSI, UF8, Unicode oder ASCII. Die Anwendung ist selbsterklärend. Da die Dateien einfach überschrieben werden, empfielt sich vor Anwendung ggf. eine Sicherungskopie der Originaldateien.
Das Tool kann hier als Stand-Alone-EXE von meinem Server heruntergeladen werden.
CDI-Subkorpus-Bilder
Ein inzwischen recht umfangreiches und stabiles Tool, mit dessen Hilfe sich sehr große Textmengen in kleinere, thematisch relevante Subkorpora zerteilen und bei Bedarf direkt in AntConc laden lassen.
Das Tool kann hier als Stand-Alone-EXE von meinem Server heruntergeladen (32bit-Version / 64bit-Version) werden.
KontraKorp
KontraKorp ist ein kleines Tool zur kontrastiven Auswertung von Belegfrequenzen und Belegfrequenzlisten mit Hilfe statistischer Maße (Signifikanztests).
Anwendungsbereich: Korpuslinguistische, statistische Auswertung von Kookkurrenz-Listen, Wortlisten (Ermittlung von Keywords), NGramm-Listen u.ä. Funktionsumfang: Manuelle und automatische (Listen) Berechnung von Chi-Square und LLR-Wert auf Basis der dazugehörigen Signifikanztests. Kurze Anleitung im Programm. Betriebssysteme: Windows.
Die aktuelle Version von KontraKorp (v1.0) kann hier als Stand-Alone-Programm (keine Installation nötig) und unter den Bedingungen der Creative Commons Licence heruntergeladen werden.